はじめに
Azure Synapse Analytics で分析を行っていきます。サーバーレスSQLプールを利用して分析を行います。

すでにワークスペースが作成されていることをが前提条件です。

ワークスペースを作成するとサーバーレスSQLプールも組み込まれています。
データ分析
ニューヨーク市のタクシー データを分析しておきます。
Synapse Studioを開きます。
開発から新しいSQLスクリプトを作成します。
下記のSQLが実行できることを確認します。
URLは作成した環境に合わせて変更します。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquet',
FORMAT='PARQUET'
) AS [result]
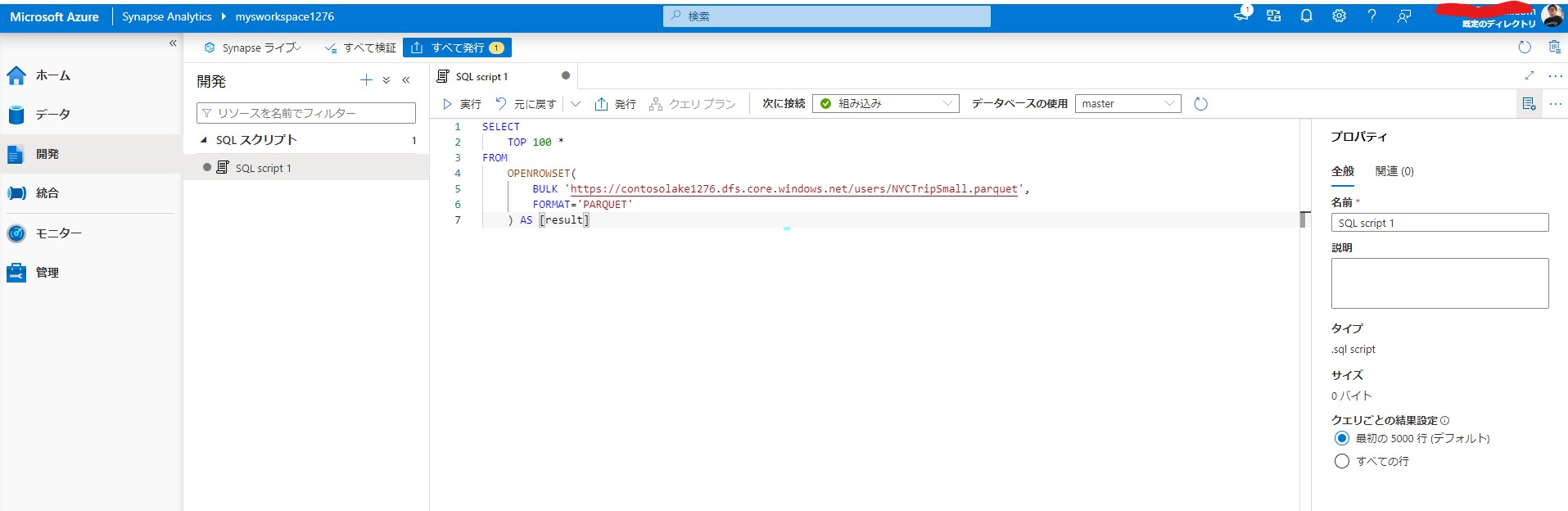
実行すると上位100行の結果が返ってきます。
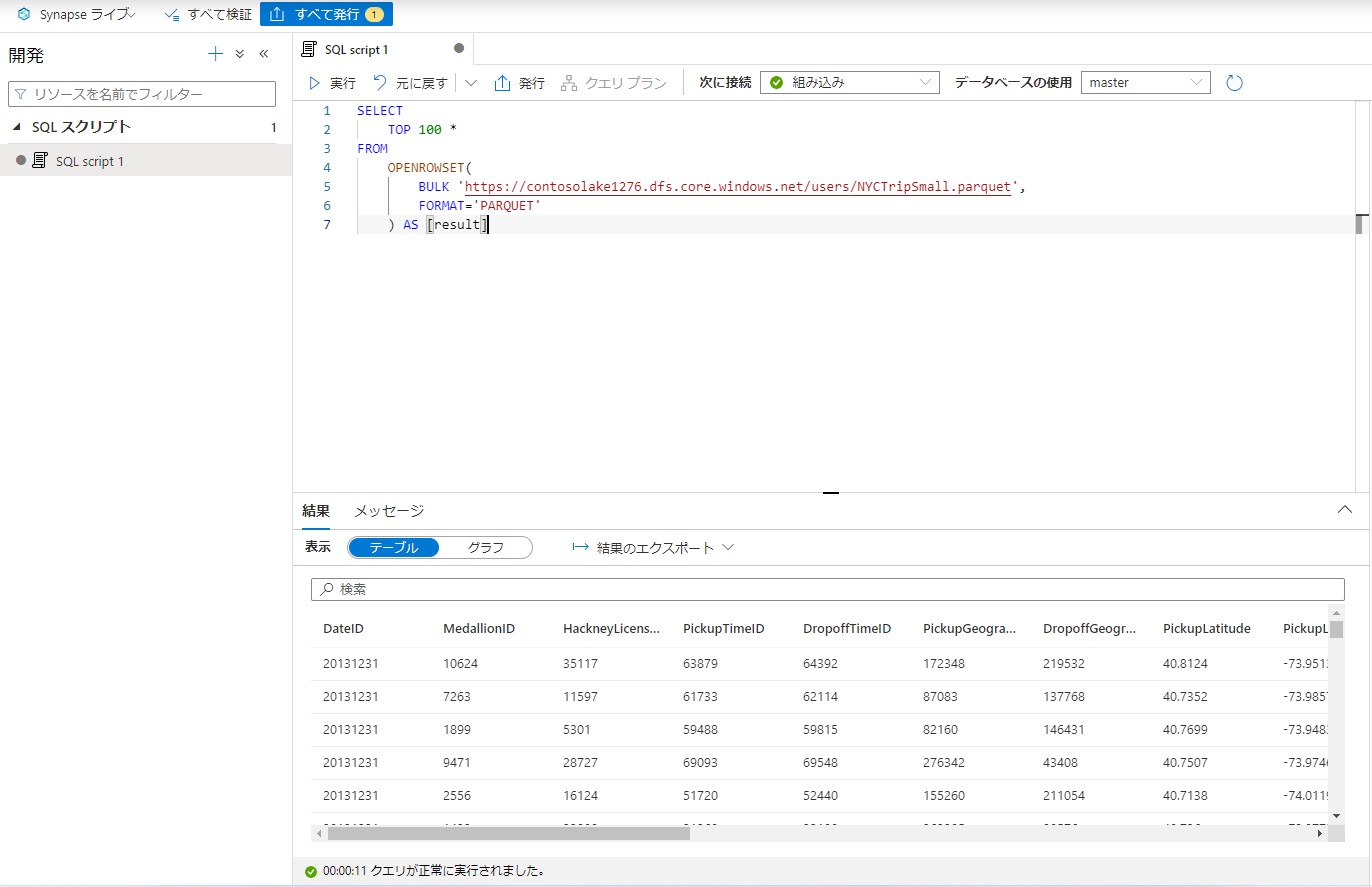
データベースの作成
分析用のデータベースを作成します。
CREATE DATABASE DataExplorationDB
COLLATE Latin1_General_100_BIN2_UTF8
データベースが作成されていることを確認します。

使用するデータベースを変更します。SQLで変更するか、ポータルで変更します。
資格情報やデータ ソースなどのユーティリティ オブジェクトを作成します
CREATE EXTERNAL DATA SOURCE ContosoLake WITH ( LOCATION = 'https://contosolake.dfs.core.windows.net')
外部データにアクセスするためにDataExplorationDB でユーザを作成します。
CREATE LOGIN data_explorer WITH PASSWORD = 'パスワード';
DataExplorationDBに作成したユーザにADMINISTER DATABASE BULK OPERATIONS の権限を与えます。
CREATE USER data_explorer FOR LOGIN data_explorer; GO GRANT ADMINISTER DATABASE BULK OPERATIONS TO data_explorer; GO
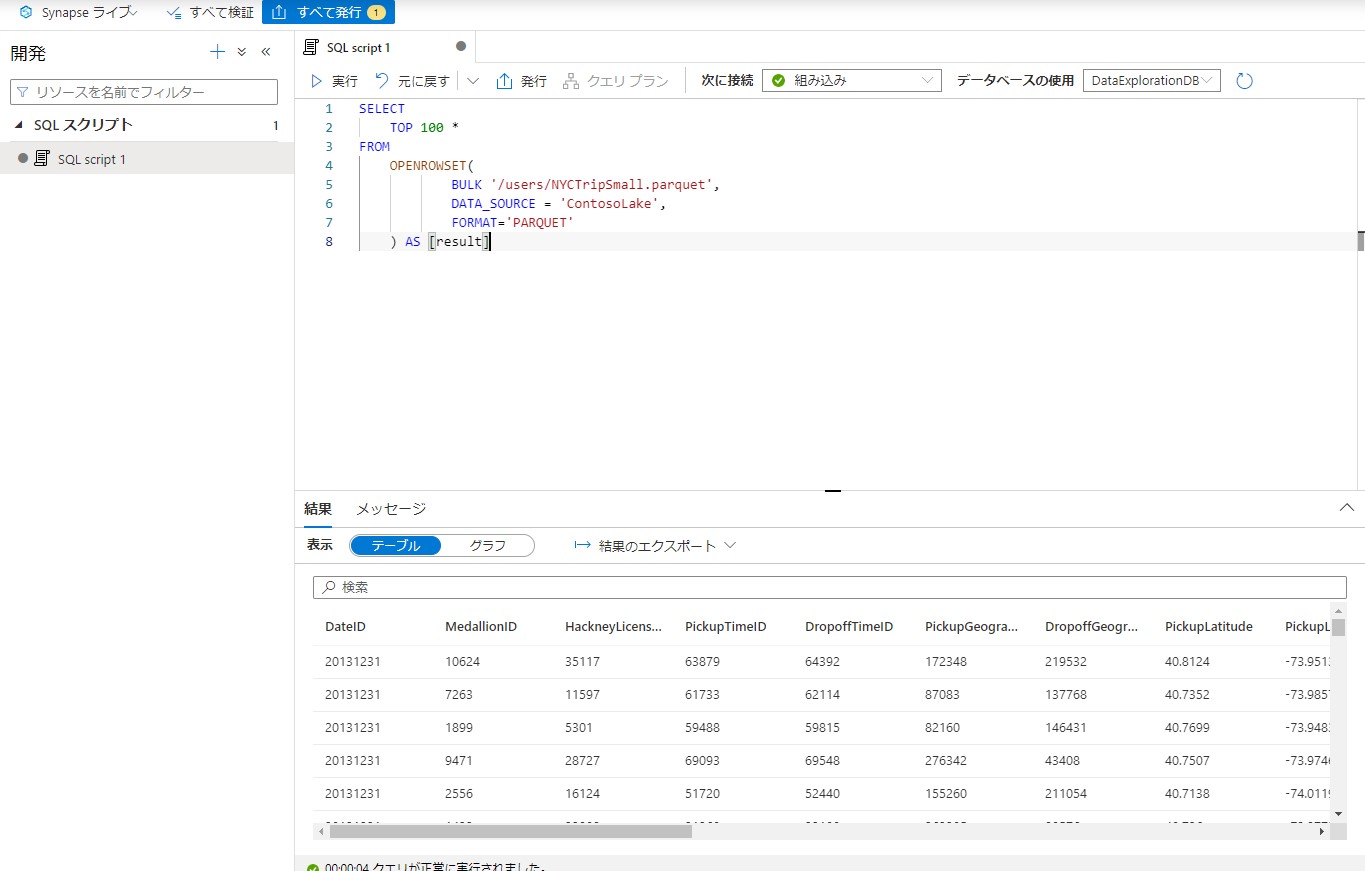
相対パスとデータ ソースを使用してファイルの内容を探索します。内容が表示されることを確認します。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '/users/NYCTripSmall.parquet',
DATA_SOURCE = 'ContosoLake',
FORMAT='PARQUET'
) AS [result]
まとめ
組み込まれているサーバーレスSQLプールを利用してみました。チュートリアルは分析というよりは表示している感じでしかありません。
いまいちチュートリアルでは、実際にどのように使っていくかはつかめないと思いますが全体像を把握できるまではチュートリアルを完了することが良いと思います。