はじめに
Apache Spark for Azure Synapse で分析を行っていきたいと思います。

Synapseワークスペースは構築されていることが前提です。

分析
Apache Sparkを利用した分析は以下の作業手順で行います。
- サーバーレス Apache Spark プールの作成
- Spark プールでデータ分析
- データをSpark nyctaxi データベースに読み込む
- ノートブックを使用してデータを分析
サーバーレス Apache Spark プールの作成
Synapseワークスペースを作成した時に、ストレージにサンプルデータを保存しています。
それがNYCタクシーのデータです。今回は、そのサンプルデータを利用するのでない場合はSynapseワークスペースの作成を参考に配置してください。
管理からApache Sparkプールを開き新規で作成します。
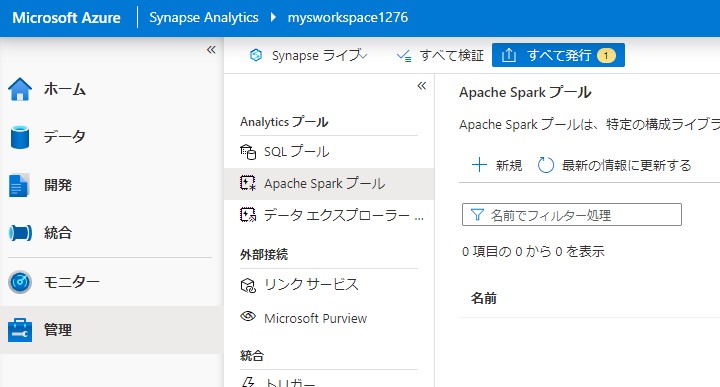
プール名を任氏で作成します。サイズファミリはメモリを選択し、サイズは最小のSmallを選択します。これで作成します。
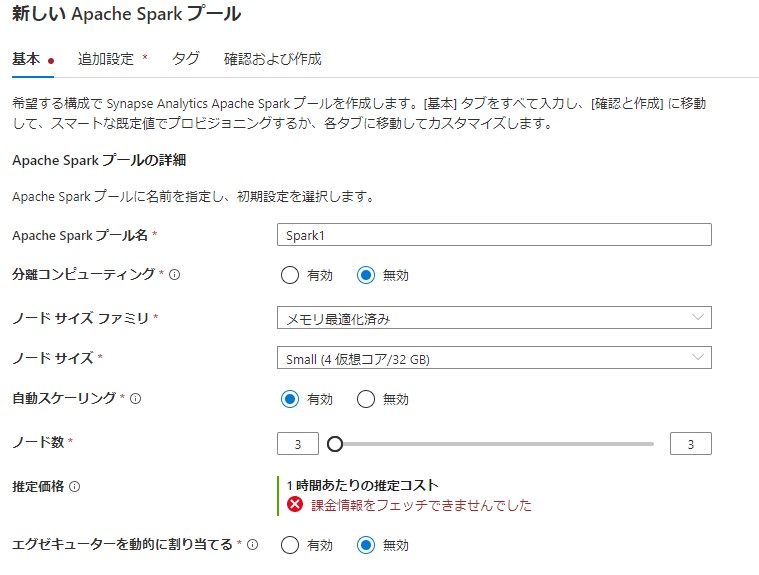
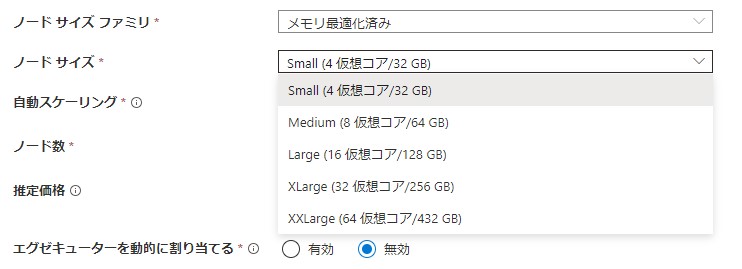
サイズファミリはメモリ最適化済み、Hardware Acceleratedから選択できます。

サイズはSmallからXXLargeまで選択できます。
Spark プールでデータ分析
Synapse studioで開発を開き、ノートブックを作成します。
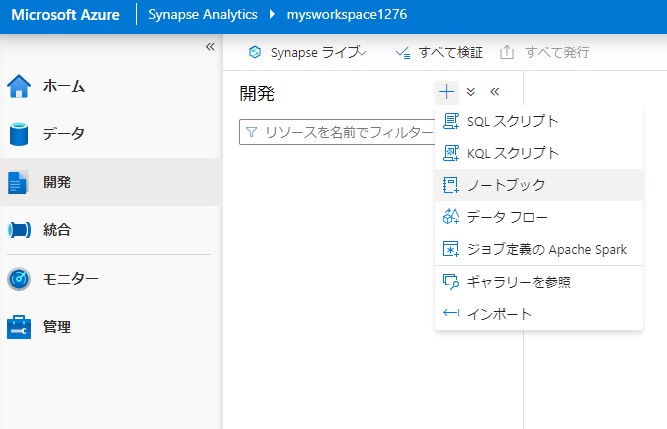
下記のコースを入力します。ただし、adfss URIは作成したストレージアカウントに読み替えて入力します。アタッチ先は上記で作成したものを選択します。
%%pyspark
df = spark.read.load('abfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet', format='parquet')
display(df.limit(10))
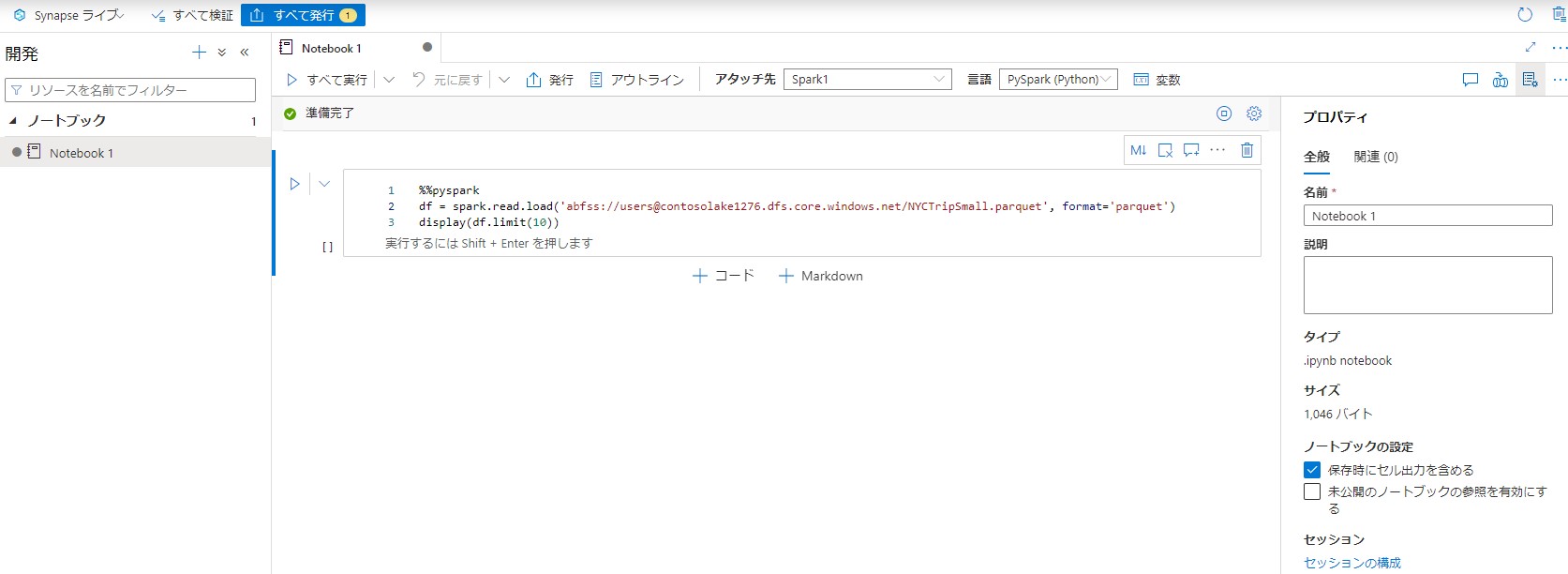
実行結果
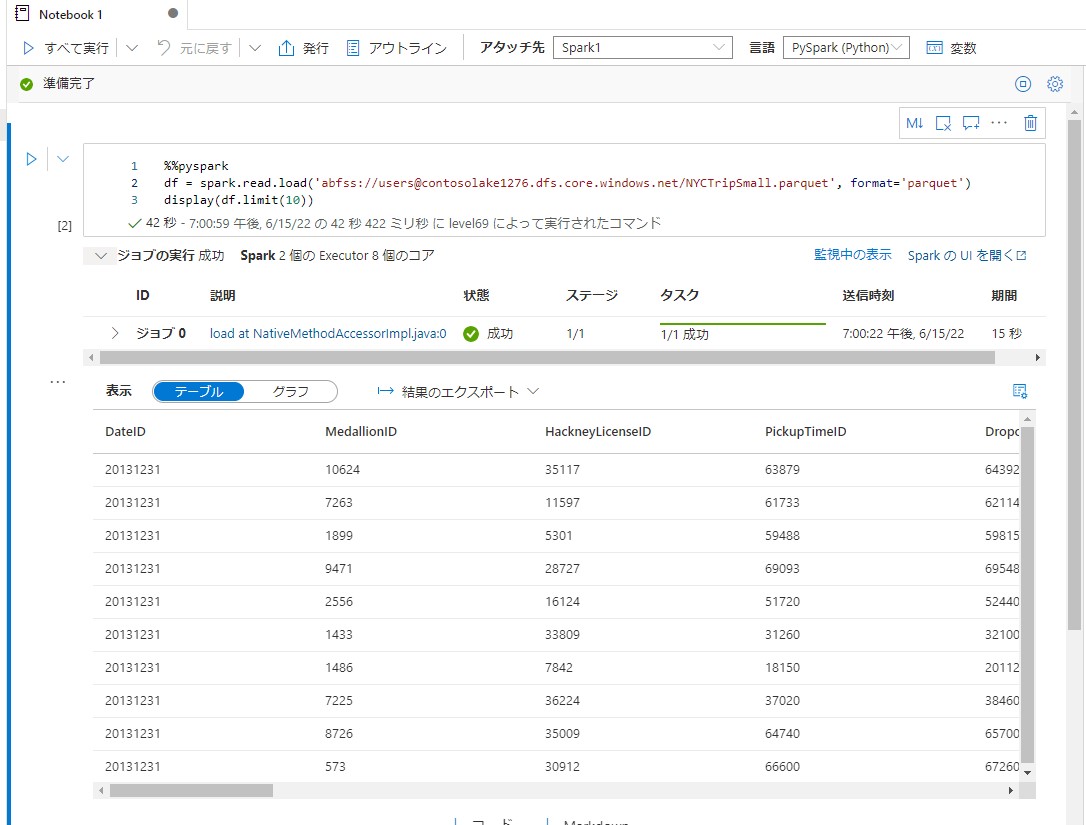
スキーマの表示
データをSpark nyctaxi データベースに読み込む
下記のコードを実行してデータベースを作成し読み込みます。
%%pyspark
spark.sql("CREATE DATABASE IF NOT EXISTS nyctaxi")
df.write.mode("overwrite").saveAsTable("nyctaxi.trip")
ノートブックを使用してデータを分析
下記のコードを実行します。
%%pyspark
df = spark.sql("SELECT * FROM nyctaxi.trip")
display(df)
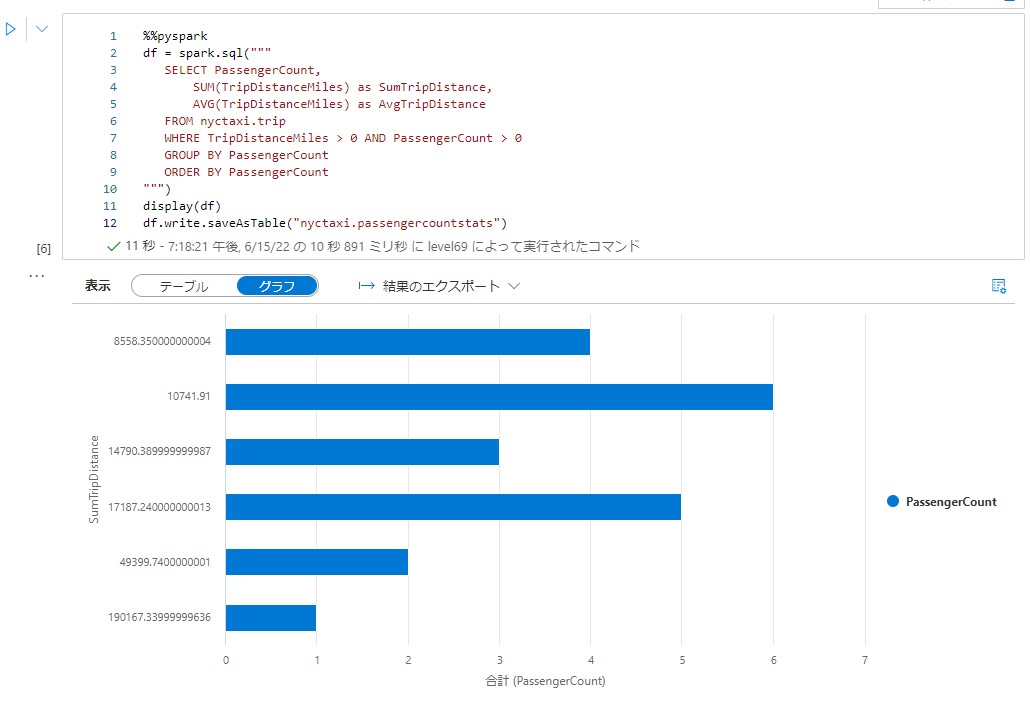
下記のコードを実行しテーブルに保存します。
%%pyspark
df = spark.sql("""
SELECT PassengerCount,
SUM(TripDistanceMiles) as SumTripDistance,
AVG(TripDistanceMiles) as AvgTripDistance
FROM nyctaxi.trip
WHERE TripDistanceMiles > 0 AND PassengerCount > 0
GROUP BY PassengerCount
ORDER BY PassengerCount
""")
display(df)
df.write.saveAsTable("nyctaxi.passengercountstats")
セルの結果でグラフを表示します。
まとめ
以上のような手法で分析を行っていきます。分析を行える言語が変わってきます。Python、Scala、C#、Spark SQLが利用できます。必要に応じて変えるとよいと思います。