はじめに
SQLプール で分析を行っていきたいと思います。

これはサーバーレスSQLプールとは異なり組み込まれているものではなく、専用のSQLプールを作成し分析を行います。

Synapseワークスペースは構築されていることが前提です。
分析
SQLプール を利用した分析は以下の作業手順で行います。
- 専用 SQL プールを作成
- データをプールに読み込む
- データを分析
専用 SQL プールを作成
Synapse studioの管理からSQLプールを開きます。
新規で作成します。
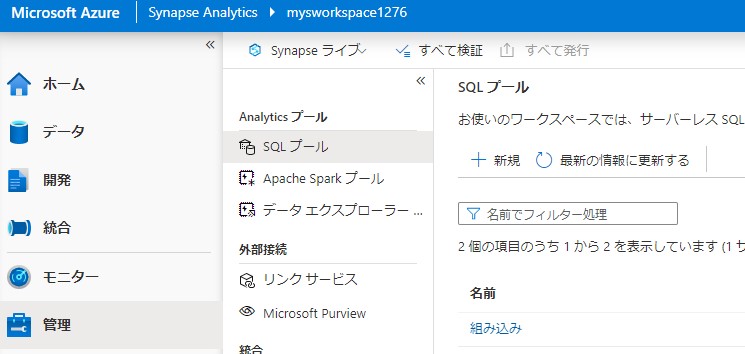
名前を任意に入力し、パフォーマンスを最小にします。1時間あたりの費用もそれなりにかかるので最小でも注意が必要になると思います。間違って削除し忘れると12万円超えます。ただし、一時停止することで課金を停止することが出来ます。高い理由としては、専用SQLプールは以前のSQL DWだからです。
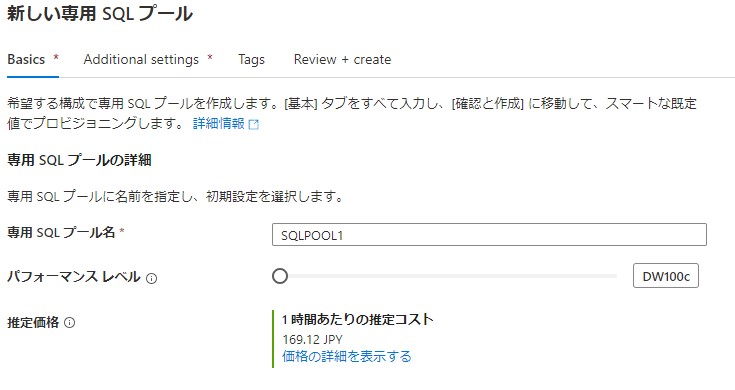
SQLプールが専用で作成されていることが確認できます。一時停止も行えます。
データをプールに読み込む
開発からSQLスクリプトを新規で作成します。
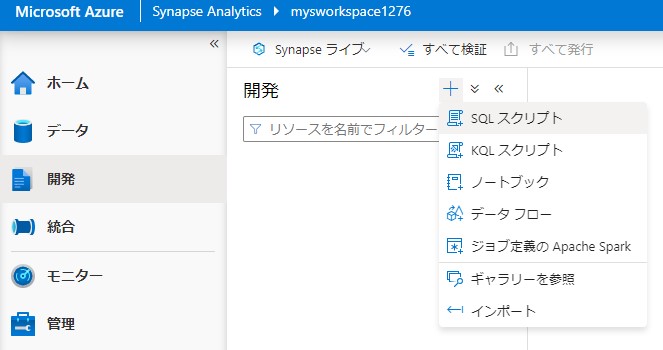
作成したSQLプールを選択します。

下記このコードを実行します。読み込むストレージアカウントのURLは保存したURLに読み換えてください。
IF NOT EXISTS (SELECT * FROM sys.objects O JOIN sys.schemas S ON O.schema_id = S.schema_id WHERE O.NAME = 'NYCTaxiTripSmall' AND O.TYPE = 'U' AND S.NAME = 'dbo')
CREATE TABLE dbo.NYCTaxiTripSmall
(
[DateID] int,
[MedallionID] int,
[HackneyLicenseID] int,
[PickupTimeID] int,
[DropoffTimeID] int,
[PickupGeographyID] int,
[DropoffGeographyID] int,
[PickupLatitude] float,
[PickupLongitude] float,
[PickupLatLong] nvarchar(4000),
[DropoffLatitude] float,
[DropoffLongitude] float,
[DropoffLatLong] nvarchar(4000),
[PassengerCount] int,
[TripDurationSeconds] int,
[TripDistanceMiles] float,
[PaymentType] nvarchar(4000),
[FareAmount] numeric(19,4),
[SurchargeAmount] numeric(19,4),
[TaxAmount] numeric(19,4),
[TipAmount] numeric(19,4),
[TollsAmount] numeric(19,4),
[TotalAmount] numeric(19,4)
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
-- HEAP
)
GO
COPY INTO dbo.NYCTaxiTripSmall
(DateID 1, MedallionID 2, HackneyLicenseID 3, PickupTimeID 4, DropoffTimeID 5,
PickupGeographyID 6, DropoffGeographyID 7, PickupLatitude 8, PickupLongitude 9,
PickupLatLong 10, DropoffLatitude 11, DropoffLongitude 12, DropoffLatLong 13,
PassengerCount 14, TripDurationSeconds 15, TripDistanceMiles 16, PaymentType 17,
FareAmount 18, SurchargeAmount 19, TaxAmount 20, TipAmount 21, TollsAmount 22,
TotalAmount 23)
FROM 'https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquet'
WITH
(
FILE_TYPE = 'PARQUET'
,MAXERRORS = 0
,IDENTITY_INSERT = 'OFF'
)
実行か完了すると200万行のデータがSQLプールに読み込まれます。
データを分析
読み込まれたデータを分析します。
データからSQLデータベースを開きます。テーブルからdb.NYCTaxiTripSmallの「・・・」を開きます。
新しいスクリプトから上位100行を選択します。
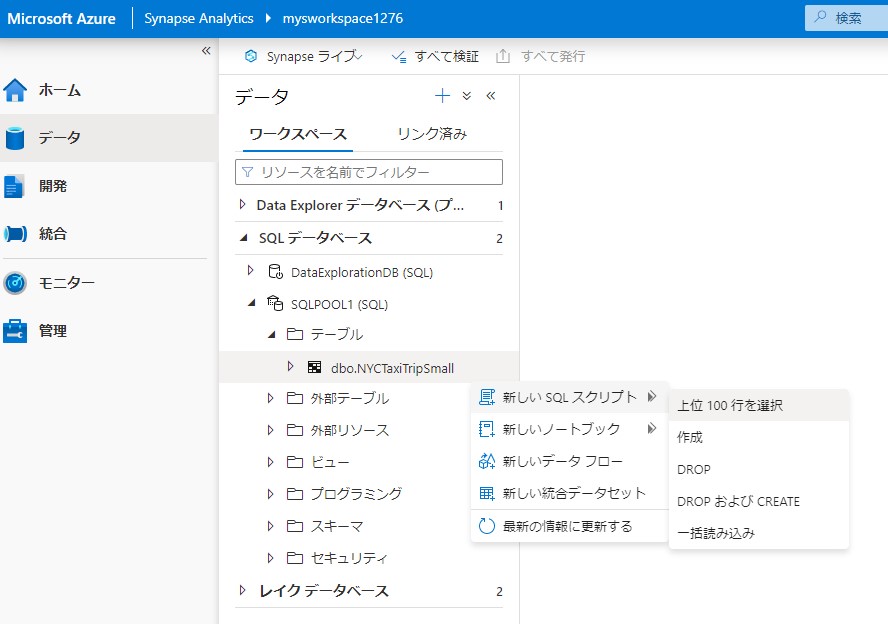
SQLが生成され100行表示されます。
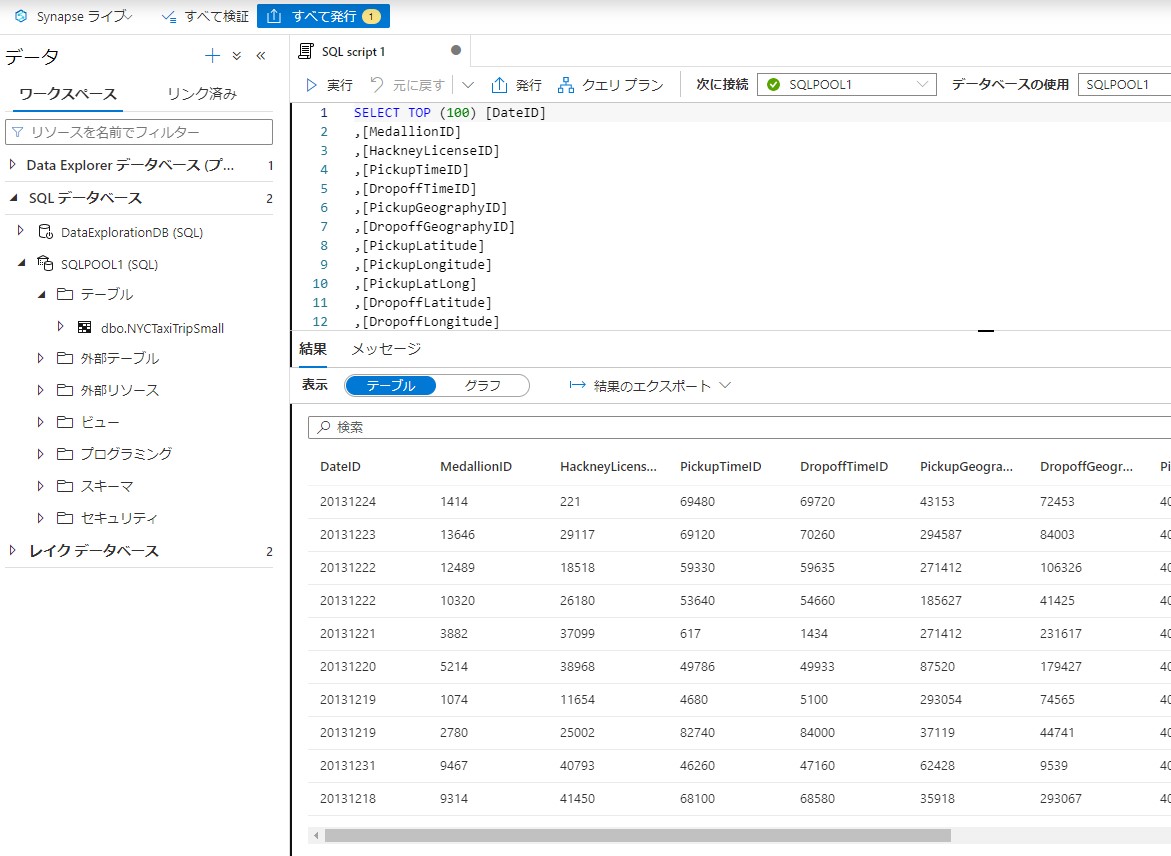
作成されたSQLスクリプトを下記に置換でします。乗車時間と乗客数の相関を表示します。
スクリプトは新規に作成しても問題ありません。
SELECT PassengerCount,
SUM(TripDistanceMiles) as SumTripDistance,
AVG(TripDistanceMiles) as AvgTripDistance
FROM dbo.NYCTaxiTripSmall
WHERE TripDistanceMiles > 0 AND PassengerCount > 0
GROUP BY PassengerCount
ORDER BY PassengerCount;
実行後にグラフで表示すると分かりやすく確認できます。
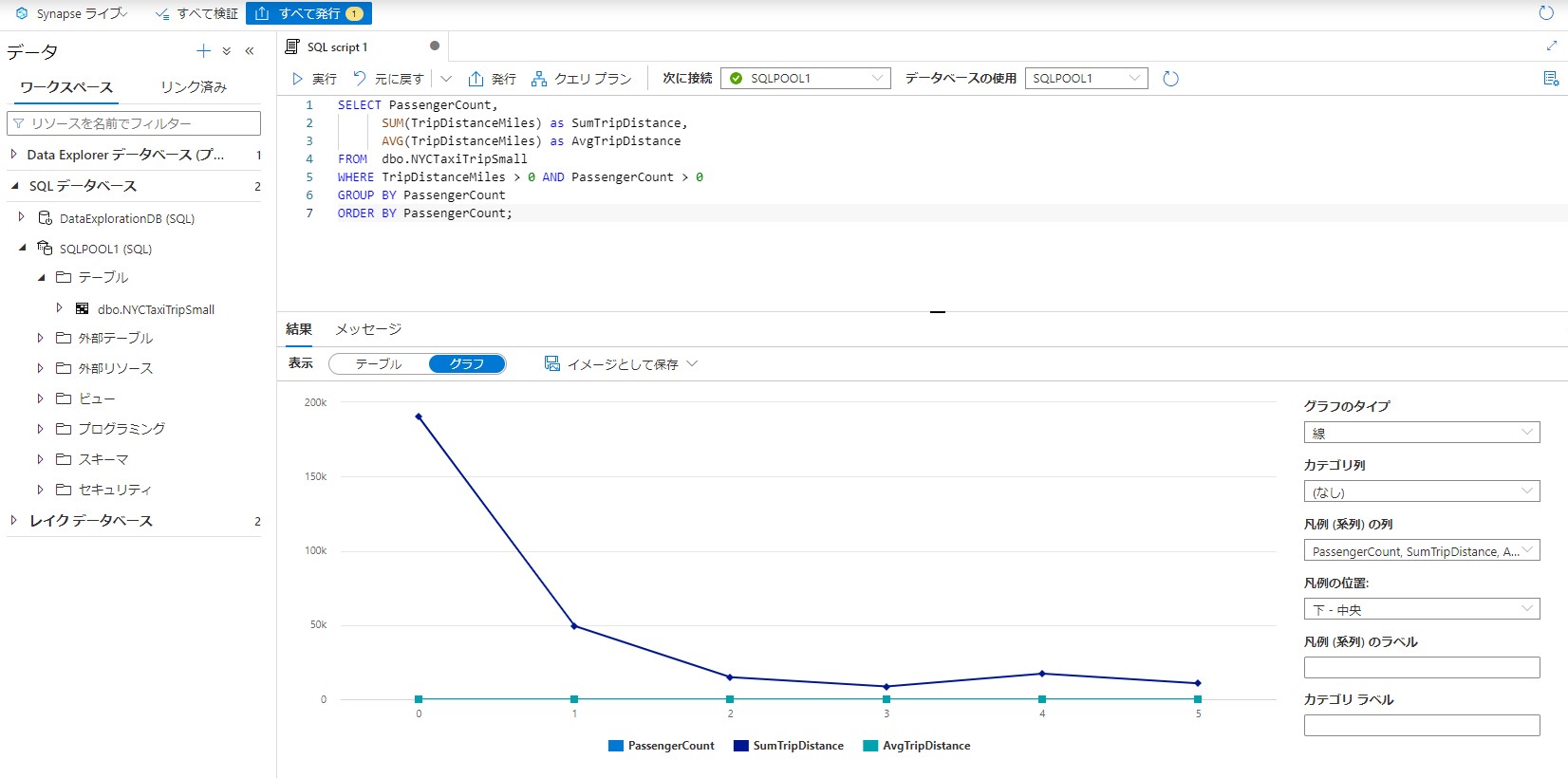
これで専用SQLプールと利用した分析は完了です。
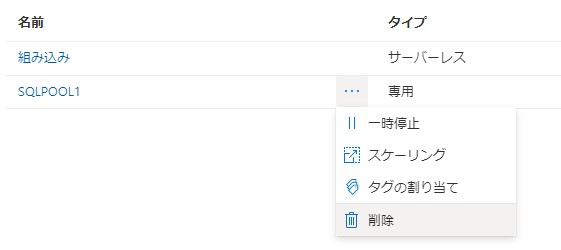
作成したSQLプールは削除するか一時停止しましょう。
まとめ
専用SQLプールを利用する方法を紹介しました。コストなど見合った分析に利用することが必要だと思います。