はじめに
くどうです。
先日、fluentd によるKubernetesでのlogを取得する方法を紹介しました。
AKS ( Kubernetes ) のPod からログをfluentd を使って収集してelasticsearch + kibanaで解析する方法
Tweetしたところ @johtani さんからFilebeatを利用した方法を教えて頂いたので紹介します、
Shipping Kubernetes Logs to Elasticsearch with Filebeat
https://www.elastic.co/blog/shipping-kubernetes-logs-to-elasticsearch-with-filebeat
fluentdの代わりにFilebeatは入るイメージです。
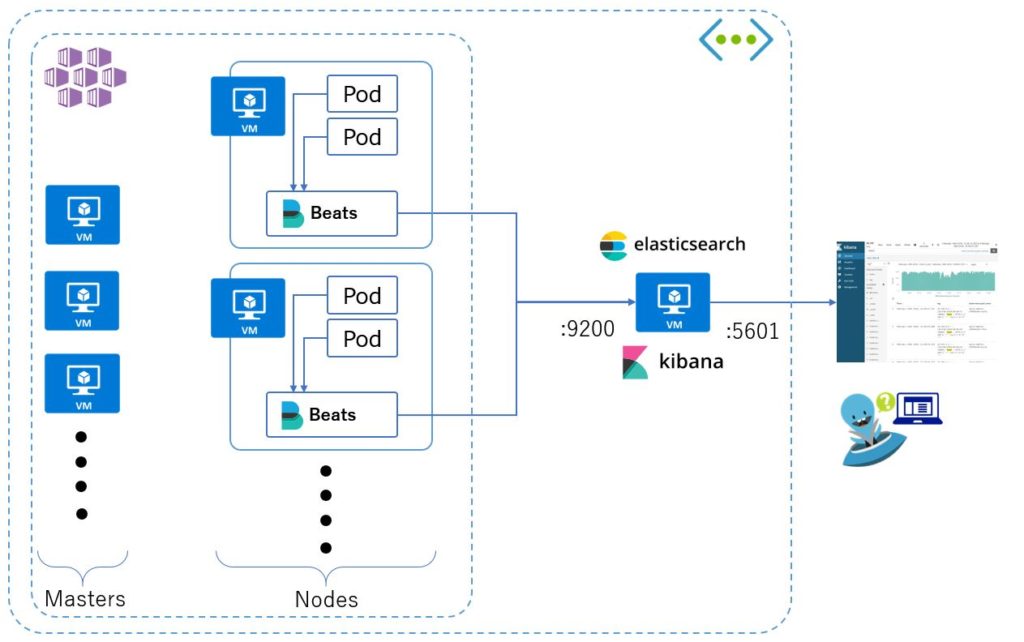
準備と展開
elasticsearch + kibana 環境の構築は下記に記載しています。
https://level69.net/archives/25379
filebeatの展開はfluentdと同様、マニフェストを利用してDaemonSetを展開します。
curl -L -O https://raw.githubusercontent.com/elastic/beats/6.0/deploy/kubernetes/filebeat-kubernetes.yaml
環境変数を修正します。
主に ELASTICSEARCH_HOST をelasticsearchのホスト名もしくはIPアドレスを指定します。
・・・・
env:
- name: ELASTICSEARCH_HOST
value: "10.240.0.7"
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
・・・・
展開します。
kubectl create -f filebeat-kubernetes.yaml
kubectlにて正しく展開されているのが確認できます。
$ kubectl get ds -n=kube-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE filebeat 3 3 3 3 3 <none> 6h kube-proxy 3 3 3 3 3 beta.kubernetes.io/os=linux 2d kube-svc-redirect 3 3 3 3 3 beta.kubernetes.io/os=linux 2d
以上で完了です。
簡単ですね。
確認
kibanaの利用方法は割愛します。
負荷テストを行ってみると以下の様にログが送られていることが分かります。
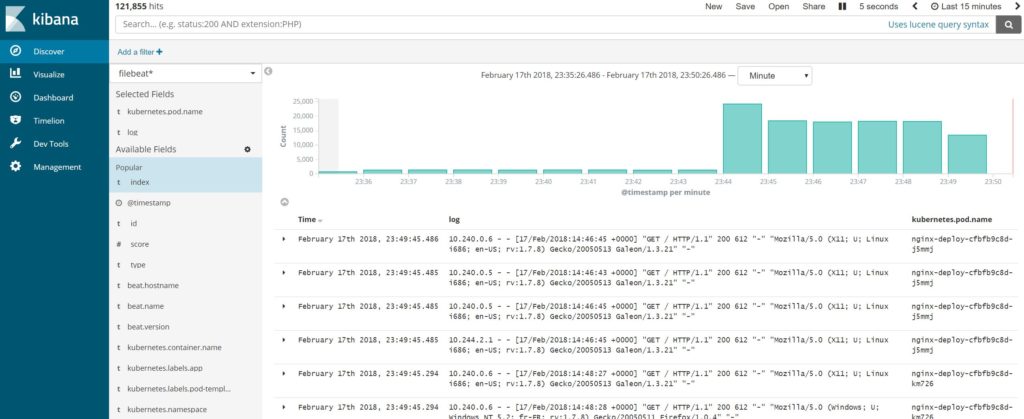
以上で設定自体は完了です。
削除
DaeamonSetの削除
kubectl delete ds filebeat -n=kube-system
まとめ
Filebeatもfluentdと同様、ログを取得できます。詳しくは確認していませんがFilebeatの方が取得できるログ情報が多いと思います。
Index Patternを作成するとfieldsが多いです。その分、同じにIndexに色々とぶっこめば解析がしやすいメリットがあるのかな?(小並感
先日、試したfluentdはkubernetesに絞っているようです。
実際に、パフォーマンスや環境に合わせて導入が必要となると思います。
参考:
https://www.elastic.co/blog/shipping-kubernetes-logs-to-elasticsearch-with-filebeat
https://www.elastic.co/guide/en/beats/filebeat/6.0/running-on-kubernetes.html