はじめに
ストレージアカウントにあるデータを分析行っていきたいと思います。

Synapseワークスペースは構築されていることが前提です。

サーバーレス Apache Spark プールのクイックスタートでnyctaxi.passengercountstatsに分析結果が保存されていることが前提です。
分析
Synapse studioを開きます。
開発からノートブックを新規作成します。
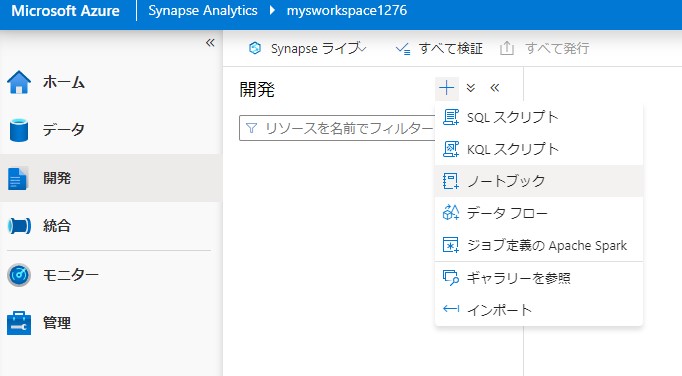
以下のコードど実行し、分析用のファイルを作成します。
%%pyspark
df = spark.sql("SELECT * FROM nyctaxi.passengercountstats")
df = df.repartition(1) # This ensures we'll get a single file during write()
df.write.mode("overwrite").csv("/NYCTaxi/PassengerCountStats_csvformat")
df.write.mode("overwrite").parquet("/NYCTaxi/PassengerCountStats_parquetformat")
アタッチ先をSparkプールに設定し実行します。
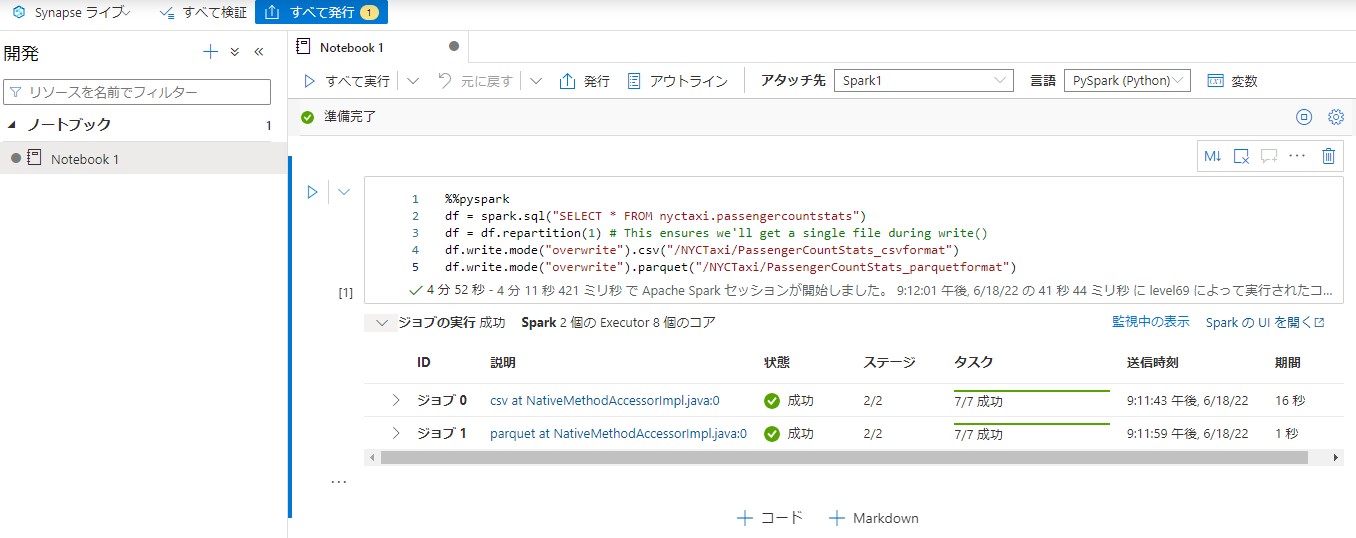
実行後、データからリンク済みを開きます。2つのフォルダが作成されていることを確認します。
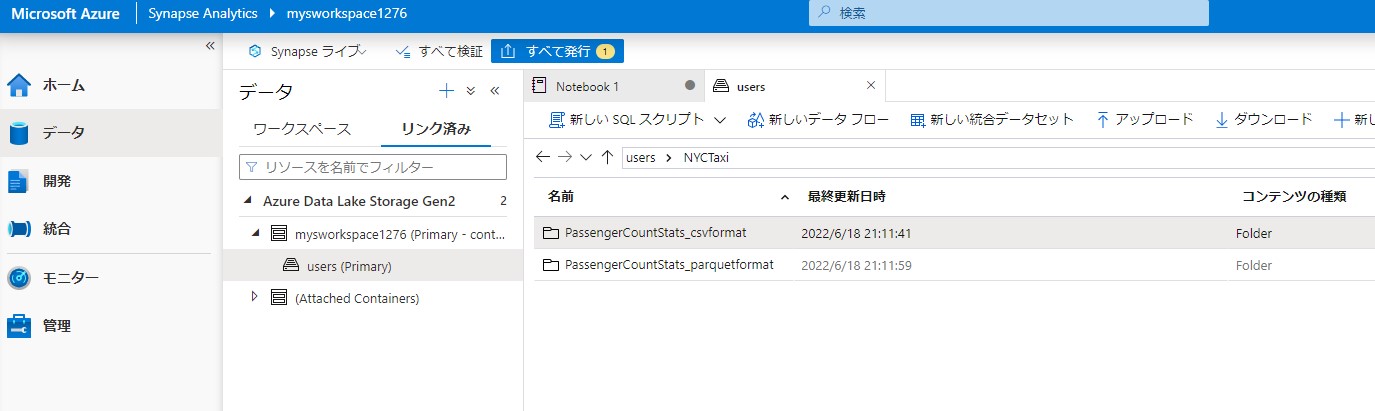
PassengerCountStats_parquetformatの中にあるファイルを右クリックして新しいノートブックを作成します。
DataFrameに読み込むを選択します。コードが自動生成されます。
生成されるコードを実行します。エラーが表示される場合は10分程度まってから再度実行します。
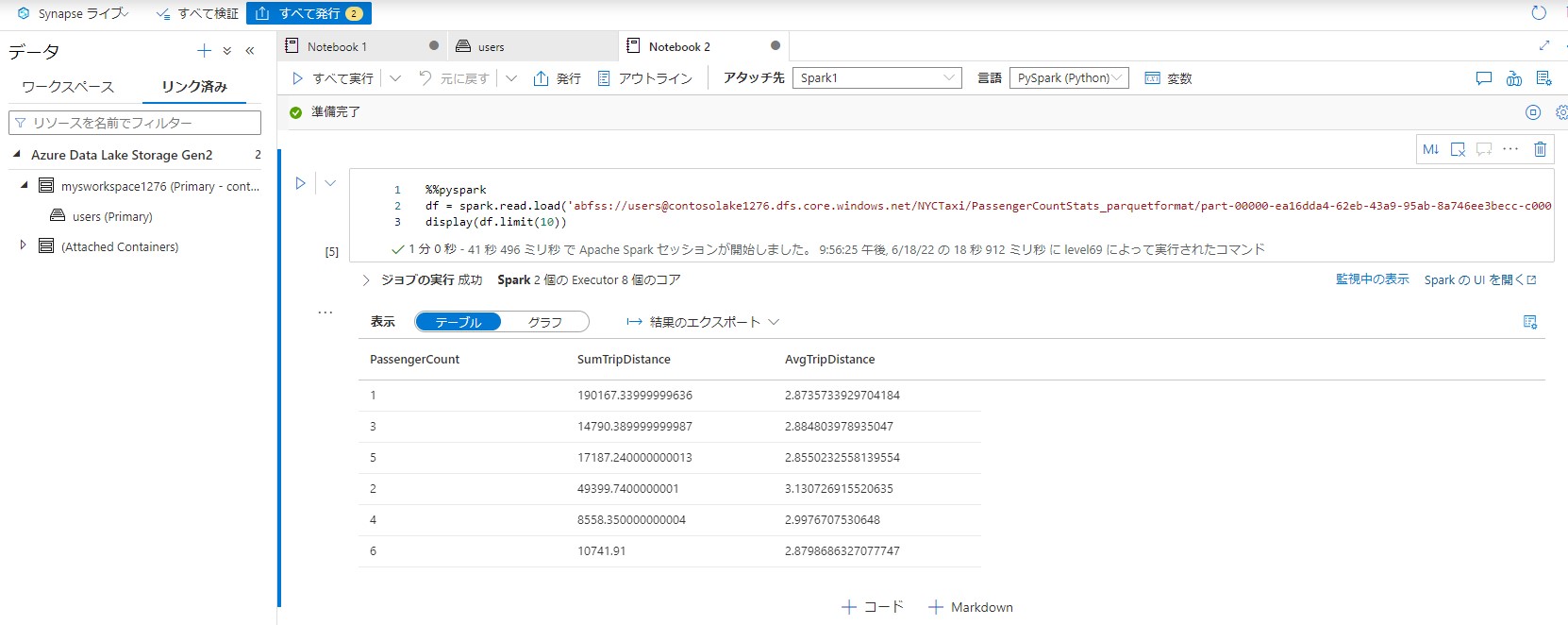
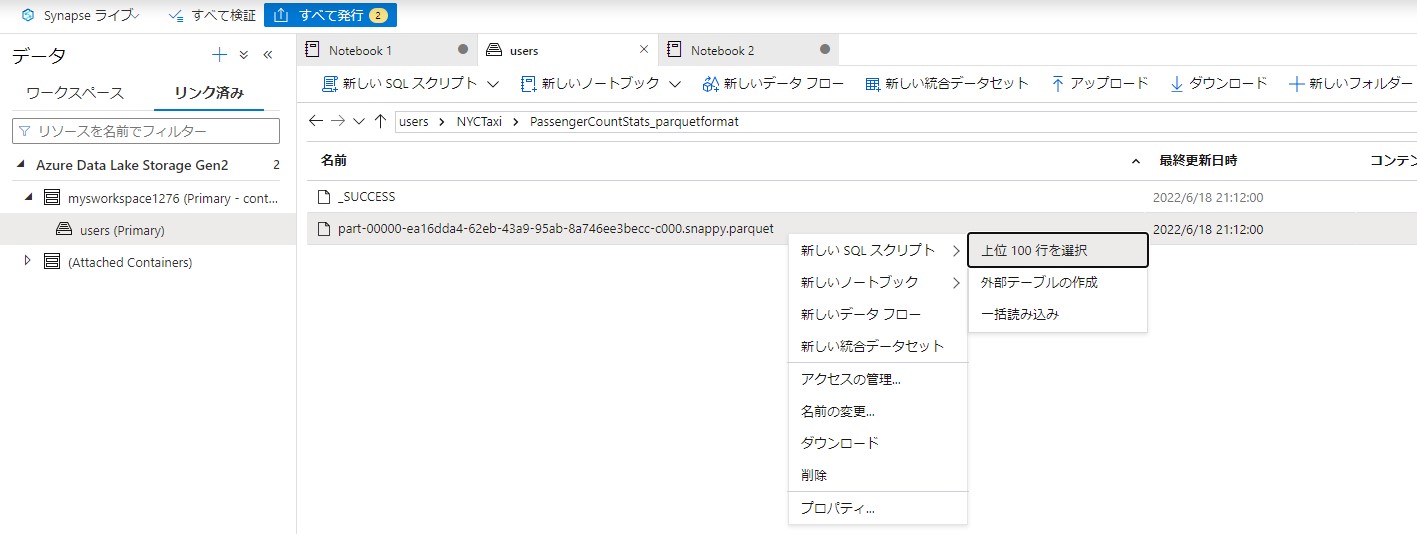
次に、再度ファイルを右クリックして新しいSQLスクリプトを作成します。
上位100行を選択します。
自動生成されるコードを実行します。これはドキュメントとは異なります。
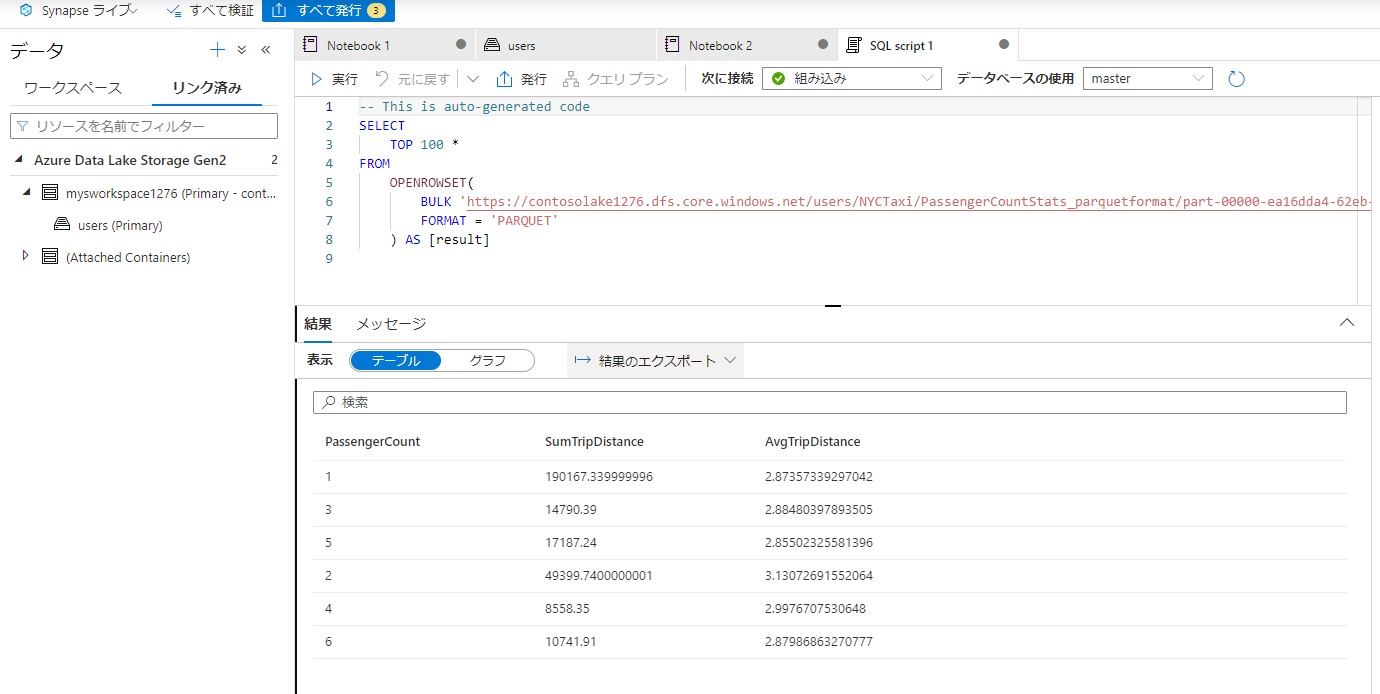
以上で分析が完了です。
まとめ
ストレージアカウントのデータを分析することが出来ました。